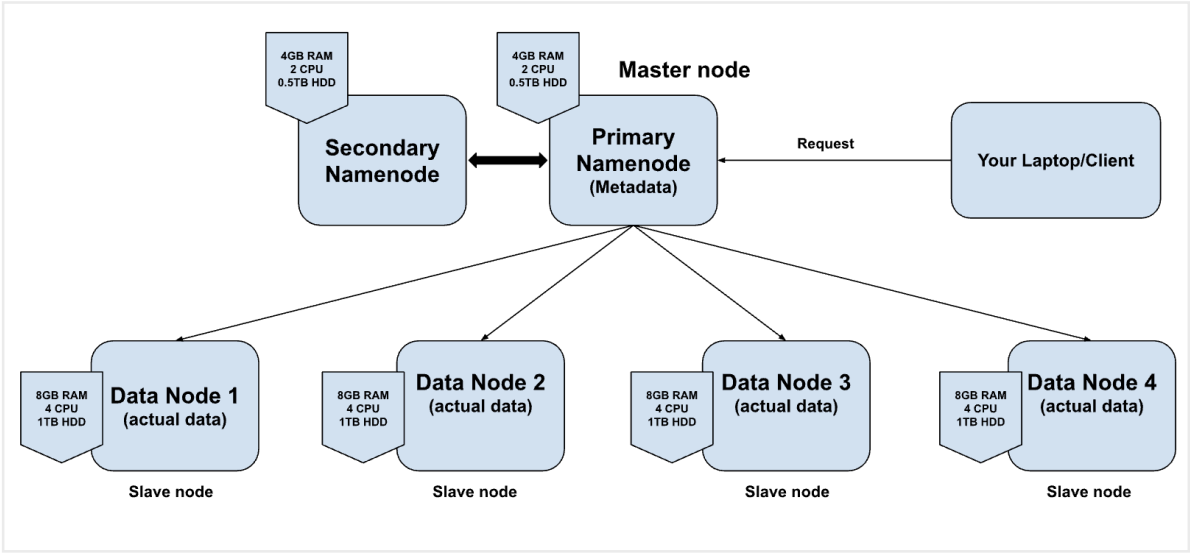
Distributes storage system (HDFS) - Explained in depth
Distributed system
- group of machines
- one machine work as master node/machine
- other machines will work as slaves
- physical thing
HDFS - store and manage the data on distributed system
1. NameNode process/program — it runs on master node — Primary NameNode
- Stores the metadata - data/information about the actual data
- Knows what is kept where
- It helps us to manage and track the directories, flies present on the data nodes
- fs-imges —> file stored on the namenode, contains the directory structure of the data stored inside HDFS (data nodes)
- edit-logs —> transactions log file —> stored the logs of transactions happening — addition of new data file, deletion of files, updates
2. DataNode process/program — runs on the slaves nodes/machines — DataNodes
- It store the actual data
How data is stored in HDFS?
If you store a file (10GB) on HDFS —> first HDFS will divide that file into smaller chunks — blocks (128MB). Then these blocks of data will be stored on the data nodes
1GB — 8 blocks (block size 128MB)
10GB — 80 blocks
customer.csv - 600MB — block size (128MB)
HDFS —> 5 blocks
b1 - 128MB,
b2 - 128MB,
b3 - 128MB,
b4 - 128MB,
b5 - 88MB
Data done 1 –> Home/data/datanode/cusomer_block1.csv - 128MB
Metadata table —> fs-image
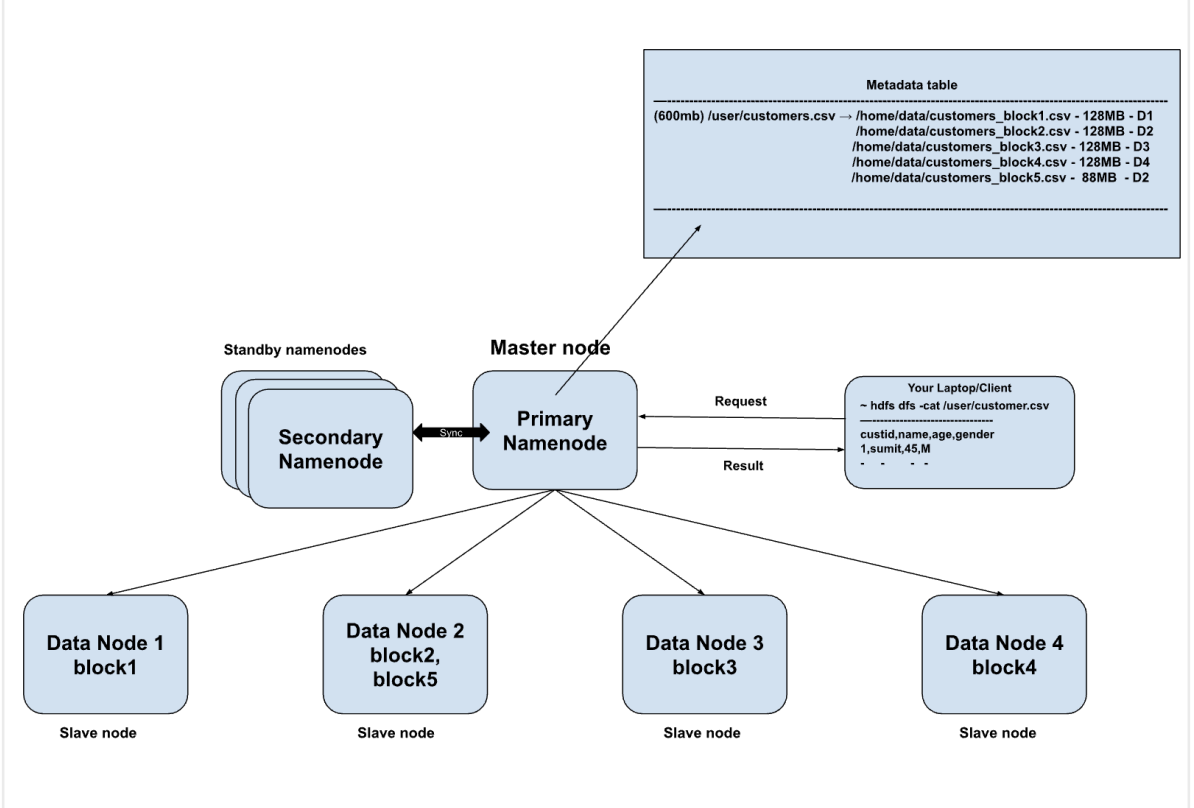
Main point of contact — Primary NameNode
If Primary NameNode fails then what will happen — SPOF — single point of failure
Secondary nameNode will take over the Primary namenode is case of failure — standby nodes
Checkpointing
- it is a process of merging the old fs-image and edit logs
- updated fs-image will be created
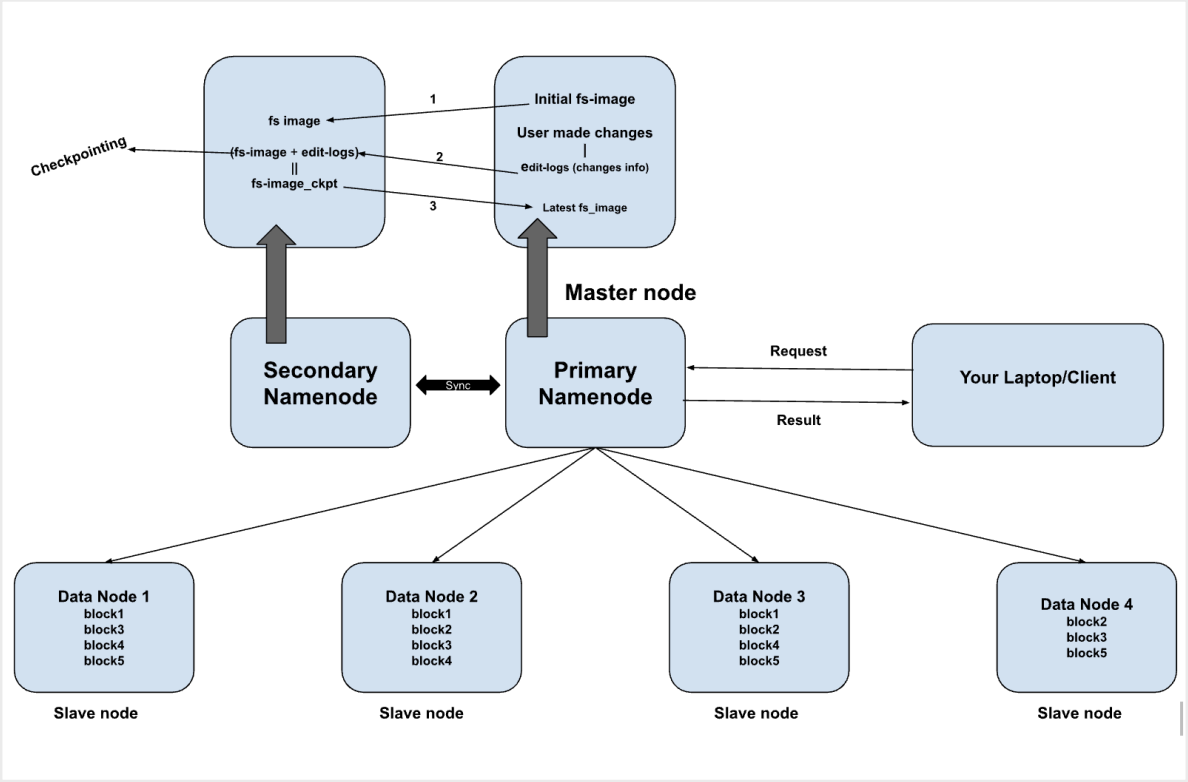
Secondary namenode helping is two ways
It helps in checkpointing —> keep updating the fs-image using the edit-logs
In case of failure it will take over the primary namenode
Fault tolerance in HDFS
HDFS maintains 3 replicas/copies of each block on different data nodes.
How these replicas are stored on data nodes.
HDFS stores replicas on two different racks
1st replica stored on data node/machine on rack 1
2nd and 3rd replicas will be stored on rack-2 but on different machines/nodes.
Rack — group of machines in data center
How will the primary Namenode get to know that the data node has failed?
Data node send heartbeats signal to primary namenode every 3 seconds, if the primary namenode does receive any signal for 10 consecutive times (30secs), then the primary namenode will assume that data node has failed.
Block size - 128MB
1GB — 8 blocks
1TB — 8000 blocks
100TB file — 8,00,000 blocks will be stored on multiple data nodes and their metadata will stored on single primary namenode
Case 1 - if we have block size < 128MB
128MB —> 8,00,000
64MB —> 16,00,000
32MB —> 32,00,000 blocks —> (data about the actual files/directories) metadata size will also become huge.
We have multiple data nodes — where actual will be stored — we can increase the number of data nodes.
We have only one namenode — huge metadata will be stored on the single namenode and it will overburden the namenode and lead to decrease in performance
Hdfs dfs -cat customer.csv — scanning huge metadata will be time consuming
— decrease the performance
File of 2 GB file
Blocks — 16
Case 2 - if we have block size > 128MB
128MB - 16 blocks
256MB - 8 blocks
512MB - 4 blocks
We are not utilizing parallelism efficiently.
Suppose we have 5 data nodes available — we have only 4 blocks to process.
Namenode federation?
- As we have seen there can multiple secondary namenodes which are used as backup/standby and will replace primary namenode in case of failure.
- Similarly we can have multiple Primary NameNodes as well, called NameNode federation/group
- It is introduced to handle the growing metadata, otherwise single primary NameNode will get overburdened.
- Metadata will be distributed across these NameNodes in NameNode federation
- It helps us to achieve the scalability