Introduction to big data and Hadoop
Let's start with the basics. How much data qualifies as 'big data'? How do we determine the size threshold for big data?
Actually, It's not solely about data size, as even a simple smartphone can store thousands of gigabytes today. Several other key factors come into play.
Key Factors:
Volume: You should be able to process the any amount of data coming to your system.
Velocity: You must process data at the speed it arrives. E.g. display sales numbers on a dashboard in real time.
Variety: You need to process all types of data, whether structured (like databases), semi-structured (like JSON files), or unstructured (like social media posts). E.g. a big data system should seamlessly handle customer reviews, sensor data, and financial records.
Veracity: Ensure data cleansing, validation, and quality control to handle inconsistencies, inaccuracies, and errors due to data diversity. E.g. customer information like names, email etc. is misspelled in a database
Value: Extract meaningful insights that benefit the business. E.g. a recommendation engine that analyzes user behavior to suggest personalized content, enhancing user satisfaction and sales.
Traditional systems struggle with big data due to their monolithic architecture, where a single machine performs all tasks. This is akin to an early-stage startup founder trying to do everything independently, limiting scalability. In monolithic architecture, increasing resources improves performance proportionally up to a certain point. Beyond that, it becomes costly and unscalable.
On the other hand, distributed systems, based on multiple machines connected via remote access protocols, process data in parallel, similar to employees in large companies collaborating. These systems are highly scalable, as you can add more machines, resulting in almost proportional performance improvements with increased resources.
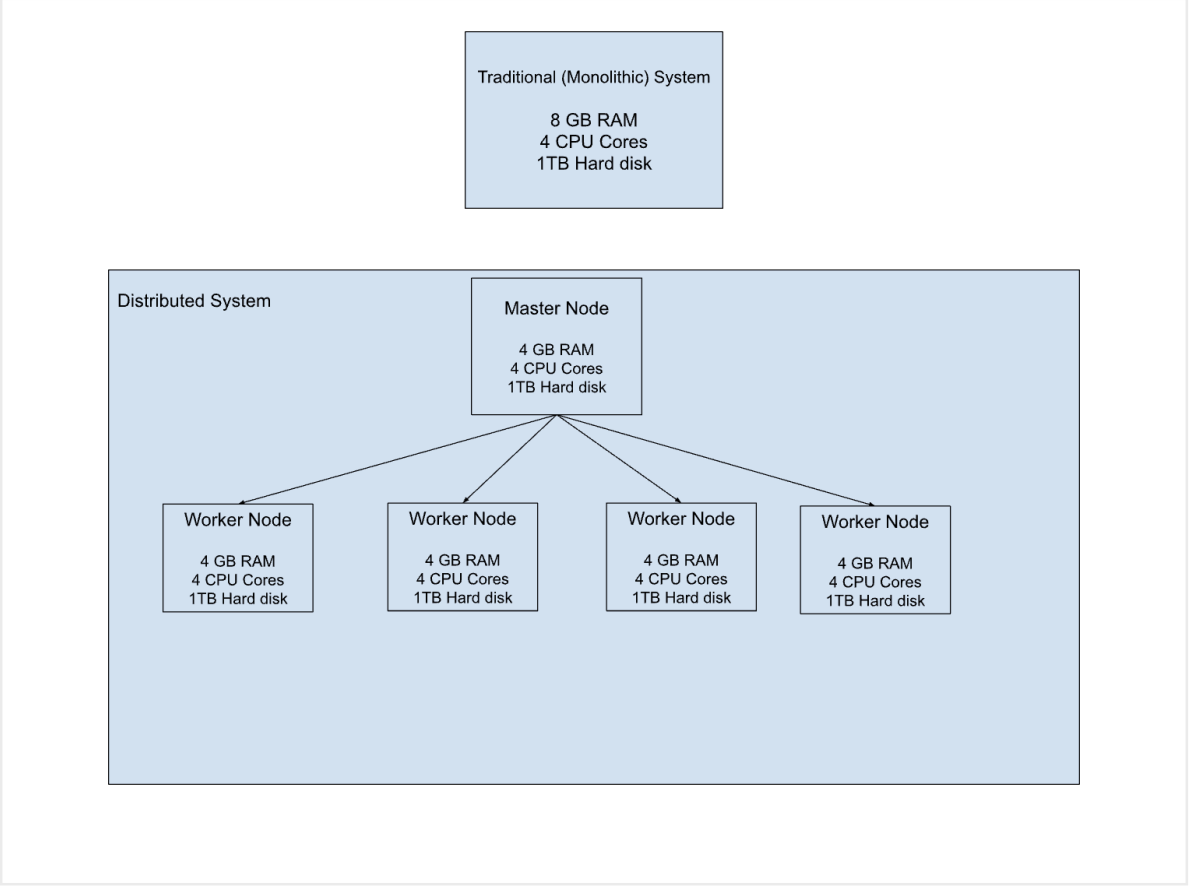
In short, processing of big data requires two essential components.
Scalable Storage: Distributed storage to accommodate vast data volumes.
Scalable Processing: A distributed processing engine for efficient data handling.
We need framework and tools using which we will be writing the logic/code and which will further processed on multiple machine on distributed system.
Hadoop — It is the first ever framework developed to build big data applications — ecosystem of tools.
Core components of Hadoop
HDFS - a distributed file system — help us to store and manage the data on distributed system
MapReduce - distributed processing engine — it will be helping us to process the big data present across multiple machines
YARN - Resource manager — allocate and manage the resources
Hadoop is the ecosystem of tools and these tools are running Mapreduce jobs internally.
Sqoop — ingestion tool
Hive — data warehousing tool
HBase — No SQL database
Pig - scripting language to clean the data
Oozie - define and orchestrate the workflow of MR jobs
Data sources → (Ingestion - Sqoop) → HDFS (Distributed storage) → Process (MapReduce) → HDFS → Analysis (Hive)
Challenges with Mapreduce
1. Learning curve is high — you need to learn multiple tools
2. You need to write a lot of code (java) to implement even a small logic
3. It only support batch processing
4. Disk based processing engine — reading the data from the disk and again writing the partially processed data into to disk
5. Slow processing
Spark came into the picture — solved all these challenges.