Types of storage systems - Databases, Data warehouse and Data lake
In this session we’ll discuss the differences between database (RDBMS), datawarehouse and data lake as these storage system will be required in order to build the scalable big data applications.
Lets first understand the terms ETL and ELT.
ETL — Extract → Transform → Load (Data storage)
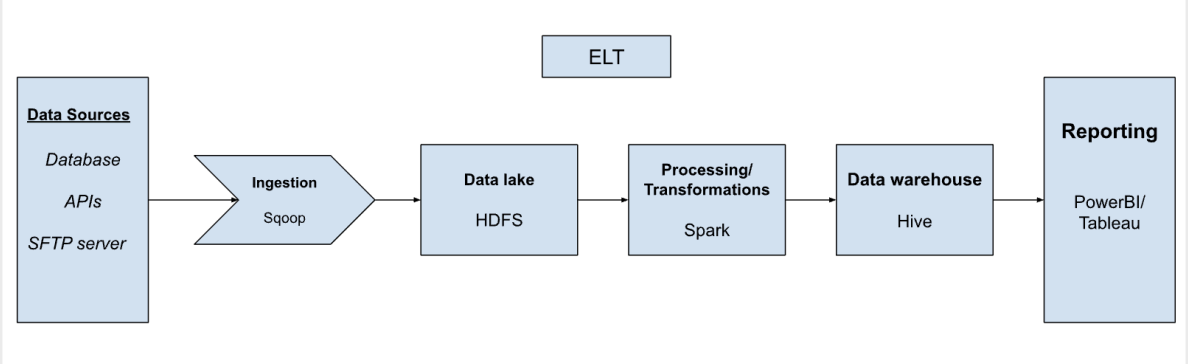
ELT — Extract → Load →Transform
(Data sources) → Extract (ingestion tool) → Load (data storage) → Transform (spark) → Load (data storage)
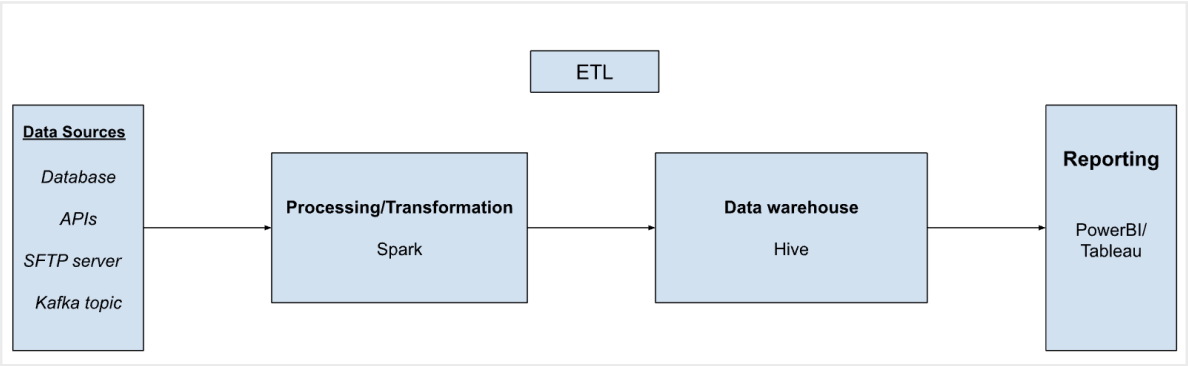
Drawbacks of ETL
- you don’t have flexibility for doing data analysis
- compulsory to do the transformations before loading the data to data storage
Databases (SQL):
1. It is mainly used to support daily operations, meant for OLTP
2. It only stores recent to provide better performance data and running complex queries may take long and also affects the other running day to day operations
3. Monolithic architecture based databases (MySQL, Oracle, Maria, etc.) and cloud based databases (distributed) (Amazon Aurora, Google Cloud Spanne, etc.)
4. It follows schema on write means while writing the data the defined table schema will be imposed for validation and if the defined schema does not match then it’ll throw an error
5. It follows en ETL process
6. Cost of storage is high
Data Warehouse:
1. It is mainly used for the historical data and meant for OLAP
2. It stores the data in structured format and mainly used for analytical purposes rather than to support the daily operations
3. Based on distributed architecture and can be scaled horizontally
4. It follows schema on write
6. It follows en ETL process
7. Cost of storage is high but less then databases. Example: Teradata, Redshift, BigQuery, etc.
Problem with ETL process: Data needs to be transformed and structured in order to load it into data warehouse. Here we lose the freedom to keep to keep the raw data and transformation needs to be done immediately after extraction.
Datalake comes to rescue: Data Lake:
1. Similar to Data Warehouse as it is also used for the historical data
2. It can store structured, semi structured and structured data and mainly used for analytical purposes rather than to support the daily operations
3. Based on distributed architecture and can be scaled horizontally
4. It follows schema on read: the data is not stored in tables, so while reading the data only the defined structured will be imposed. E.g. reading data from HDFS using Hive
5. It follows an ELT process: We can just load the extracted data from source to data lake as is. Later we think about the transformation, so here we have the flexibility and freedom for transformation.
6. Cost of storage is low. Example: HDFS, Amazon S3, GCS, ADLS Gen2, etc.